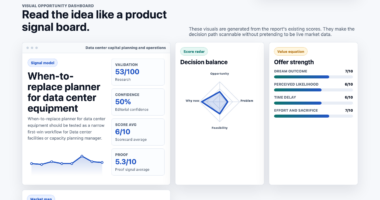
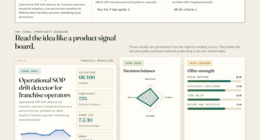
📊 Full opportunity report: Mac vs GPU Tower for Local LLMs: The Heat-and-Noise Tradeoff on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
This article compares Mac Studio with Apple Silicon to GPU towers for running local large language models, focusing on heat, noise, capacity, and performance tradeoffs. The decision depends on model size, throughput needs, and noise tolerance.
Apple Silicon-based Macs, such as the Mac Studio with M3 Ultra, offer near-silent operation and low power consumption for local large language model inference, contrasting sharply with high-performance GPU towers that generate significant heat and noise.
The core distinction lies in the architectural focus: GPUs prioritize memory bandwidth, enabling faster inference on models that fit within their VRAM, with RTX 5090 cards delivering approximately 1,792 GB/s of bandwidth. In contrast, Apple Silicon chips optimize memory capacity through a unified memory architecture, allowing up to 512GB shared across CPU, GPU, and Neural Engine, which enables running larger models like 70B+ quantized models that cannot fit in GPU VRAM. GPU towers consume hundreds of watts—often 575W or more per GPU—producing substantial heat and requiring complex thermal management to maintain quiet operation. Conversely, Macs draw a fraction of that power, operate near-silently, and generate minimal heat, making them ideal for continuous, unobtrusive use. The tradeoff is primarily between maximum throughput for models fitting in VRAM versus the ability to run larger models at slower speeds, with the GPU tower excelling in the former and Macs in the latter.Mac vs GPU tower
for local LLMs.
What if you sidestep the heat entirely with a different kind of machine? A tower is a high-bandwidth furnace you spend five levers quieting. Apple Silicon is near-silent by design — but asks for different tradeoffs. Match your priority in Part 2.
Put the loud, hot machine where its noise doesn’t matter, and the quiet one where you do. SSH into the tower when you need raw power; let the Mac handle everything else, silently.
Implications for Local AI Hardware Choices
This comparison influences decisions for AI practitioners, hobbyists, and organizations by highlighting that GPU towers deliver higher inference speeds for smaller models, while Macs excel in running larger models silently and efficiently. The choice impacts operational costs, noise levels, thermal management, and upgradeability, shaping how and where local AI workloads are deployed. For users prioritizing quiet, always-on operation, the Mac offers a compelling alternative, while high-throughput applications still favor GPU towers despite their heat and noise challenges.
Apple 2023 MacBook Pro with Apple M3 Max chip, 16-inch, 48GB RAM, 1TB SSD, Space Black (Renewed)
SUPERCHARGED BY M3 PRO OR M3 MAX — The Apple M3 Pro chip, with a 12-core CPU and...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Evolution of AI Hardware for Local Large Language Models
Traditionally, GPU towers with NVIDIA hardware have been the standard for local AI inference and training, emphasizing high bandwidth and CUDA ecosystem compatibility. Recent developments in Apple Silicon, with increased memory capacity and unified architecture, challenge this paradigm by enabling larger models to run locally without the thermal and noise burdens of GPUs. This shift reflects broader trends toward energy-efficient, silent computing for AI workloads, especially for users with space or noise constraints. The debate has intensified as hardware options diversify, but fundamental architectural differences remain central to performance and usability considerations."The heat-and-noise dimension of AI hardware is one of the sharpest differences between GPU towers and Apple Silicon machines, fundamentally affecting how they are used."
— Thorsten Meyer

Ace Computers Logicad Neuron Z AI Workstation | AMD EPYC 9535 (Up to 4.3 GHz) | RTX PRO 6000 | 256GB DDR5 | 2x2TB NVMe | Windows 11 Pro | Workstation for AI, ML, DL, 3D
[ENTERPRISE-CLASS EPYC CPU FOR HPC & AI] Powered by the AMD EPYC 9535 processor with 64 cores and...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Questions About Long-Term Scalability
It remains unclear how future GPU and Apple Silicon developments will shift these tradeoffs, especially regarding GPU memory pooling, multi-GPU scaling, and Apple's potential upgrades to memory capacity and ecosystem support. The long-term scalability and upgradeability of Macs for AI workloads are still evolving, and real-world performance on larger models or more complex tasks has yet to be fully tested.

High-Performance Gaming Desktop PC – Ryzen 7 5700X, GeForce RTX 3050 8GB, 16GB DDR4, 512GB NVMe SSD, WiFi 6 – Tower Computer Smooth, Ready for Gaming, Streaming & Productivity
Blazing-Fast Performance for Gaming & Work: Powered by Ryzen 7 5700X (8 Cores, 16 Threads, up to 4.6GHz)...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in AI Hardware Development
Expect ongoing improvements in GPU architectures, including higher bandwidth and better thermal efficiency, alongside potential enhancements in Apple Silicon's memory capacity and ecosystem support. Users should monitor hardware releases and software ecosystem updates to evaluate how these changes influence the heat, noise, and capacity tradeoffs. Additionally, more real-world benchmarking on large models will clarify the practical limits of each platform.

TEAMGROUP Elite DDR4 32GB Kit (2 x 16GB) 3200MHz (PC4-25600) CL22 Unbuffered Non-ECC 1.2V UDIMM 288 Pin PC Computer Desktop Memory Module Ram Upgrade - TED432G3200C22DC01
Adherence to JEDEC and compliance to RoHS with respect to environmental protection regulation, production and manufacturing
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Can a Mac run the same large models as a GPU tower?
Yes, a Mac with sufficient unified memory (up to 512GB) can run large models like 70B+ quantized models that do not fit in GPU VRAM, but at slower inference speeds.
Is noise a significant factor when choosing between these options?
Yes. GPU towers produce substantial heat and noise, requiring active cooling and thermal management, while Macs operate quietly and produce minimal heat by design.
Will future GPU cards improve in terms of heat and noise?
Likely. Advances in GPU design aim to improve thermal efficiency and reduce noise, but high-performance cards will continue to generate considerable heat and power draw.
Is upgradeability a key advantage of GPU towers?
Yes. GPU towers allow adding or swapping cards, whereas Macs are fixed at purchase, making upgrade paths more limited.
Which hardware is better for continuous, always-on AI inference?
Macs are better suited for always-on, low-noise operation due to their near-silent, power-efficient design, while GPU towers are better for maximum throughput on smaller models.
Source: ThorstenMeyerAI.com